Autor: Xavier Quesada Allue
Saber estimar y planificar es fundamental a la hora de encarar proyectos donde el producto necesita de un grado importante de creatividad y/o innovación, como por ejemplo los de desarrollo de software. En este artículo, presentamos algunos principios y prácticas introductorias para aprender a estimar y planificar un proyecto ágil.
Una de las características de la gestión de proyectos ágiles es el ser una actividad adaptativa en vez de predictiva. No es extraño, entonces, que los procesos de estimación y planificación en un proyecto ágil sean radicalmente diferentes a los de un proyecto tradicional.
En un proyecto tradicional, el proceso es relativamente lineal: se estima el producto a desarrollar (generalmente haciendo un desglose por etapas); se planifica el desarrollo (con la consecuente transformación de lo que antes eran estimaciones en compromisos); y luego se procede a ejecutar el plan, que por supuesto debe cumplirse al pie de la letra. Cuando las cosas comienzan a atrasarse (y siempre lo hacen) empiezan las complicaciones.
El problema fundamental de la planificación tradicional es que trata al desarrollo de software como una actividad predecible, cuando no lo es. Y este problema fundamental es lo que intenta atacar la estimación y planificación ágil. El desarrollo de software es una actividad de creación y transmutación de conocimiento. Como tal, no puede ser predicha ni estimada en forma precisa. El primer paso hacia la planificación ágil es la aceptación de este concepto.
Pero pocas organizaciones están dispuestas a embarcarse en un proyecto sin tener siquiera una idea aproximada de cuánto va a costar o cuándo va a estar terminado el producto. Si esto fuera aceptado, podríamos dedicarnos directamente a producir sin ningún tipo de estimación o planificación (lo cual tal vez no sería mala idea).
Entonces, cómo encarar la estimación y planificación de algo que no sabemos predecir?
Bueno, empecemos por refinar un poco qué significa no poder predecir el tamaño del producto. En la práctica, cualquier desarrollador senior puede dar una idea del orden de magnitud de un proyecto. Esto nos brinda lo que en inglés se denomina ballpark figure, un número grueso que nos permite ir pensando si es negocio desarrollar el producto o no. Y es lo primero que debe hacerse, ágil o no ágil. Las probabilidades de estar equivocados en un órden de magnitud son realmente bajas (en ese caso, por favor reconsiderar el titulo de «senior» de los desarrolladores). En mi experiencia, los proyectos tradicionales suelen excederse de sus estimaciones originales en numeros que van del 30% al 300%. Esto es lo que intentaremos mejorar con la técnica que explicaremos a continuación.
Las metodologías ágiles implementan muchos conceptos de Lean, el sistema de producción de Toyota. Uno de ellos es small batch sizes, que significa producir valor en lotes pequeños. El desarrollo tradicional, con sus etapas, produce todo el valor (el proyecto) en un solo lote. En todo momento, el 100% del proyecto está siendo procesado y 0% ha sido terminado. Finalmente se llega al «Dia D», el «Big Bang», donde todo el proyecto es entregado de un saque. Los métodos ágiles, por contraste, buscan entregar valor incrementalmente. En el caso del desarrollo de software, esto se consigue agregando funcionalidad en cada iteración y manteniendo siempre el producto funcionando con la funcionalidad que haya sido implementada hasta ese momento.
Objetivos como historias de usuario
Siguiendo esta línea, el primer paso en la estimación y planificación ágil es la creación del product backlog, o sea la definición del proyecto a realizar. Se puede dividir en objetivos expresados como historias de usuario (user stories), cada una aportando valor de negocios incremental e individual. Una historia es un requisito de negocio visto desde el punto de vista de un usuario. Se escriben con el siguiente formato: «Como xxx, quiero hacer yyy con el objetivo de zzz«, donde, xxx es el tipo de Usuario (quien), yyy es lo que el sistema debe permitir realizar (el qué) y zzz es el beneficio o valor buscado (el por qué).
Ejemplo:
«Como cliente del banco, quiero pedir un préstamo para poder comprar una casa» .
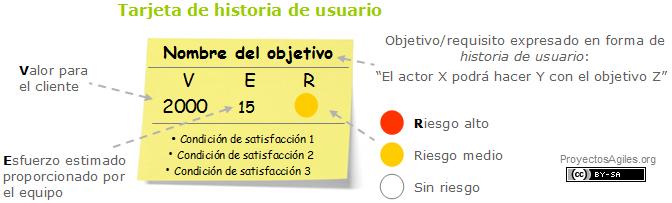
Las condiciones de satisfacción de los objetivos suelen ponerse en forma de criterios de aceptación, pruebas que se realizarán para verificar si el sistema se comporta de la manera esperada. Para ello se puede utilizar la sintaxis de BDD (Behaviour Driven Development) siguiendo el siguiente formato: «Dado aaa, cuando se produzca bbb, entonces ccc«, donde aaa es la situación en la que se encuentra el sistema, bbb es un evento que lo hará cambiar y ccc es el resultado. Esta técnica permite evitar la aparición de errores por malos entendidos y evitar retrabajar (siguiendo los principios Lean). Por ello es recomendable no empezar a desarrollar en una iteración sin antes haber escrito los casos de prueba, especialmente por que es más barato escribir texto y pensar en cómo desambiguar los requisitos que arreglar errores importantes debido a su mal entendimiento.
Pero en la práctica no hace falta usar estos formatos, cualquier sintaxis donde la acción sea clara y el beneficio buscado sea entendido por todos es suficiente. Si no partimos de cero, podemos simplemente tomar los requerimientos en cualquier formato que estén escritos (por ejemplo casos de uso).
Es importante no confundir Criterios de Aceptación de cada objetivo (requisito / historia de usuario) con la Definición de Hecho (DoD) que tienen que cumplir TODOS los requisitos.
Estimación con Planning Poker
El product backlog es, para ser exactos, una lista priorizada y estimada de historias. Por ahora sólo tenemos historias. Falta estimarlas y priorizarlas. El proceso de estimación se puede hacer utilizando una técnica llamada planning poker (póker de planificación). El objetivo del planning poker es obtener una medida de tamaño relativo de todas las historias respecto a sí mismas.

La teoría es que resulta relativamente fácil decir «A es más grande que B y que C» [no voy a entrar en detalle respecto a cómo efectuar planning poker, dejándolo para otro artículo]. Lo importante de efectuar planning poker sobre todo el backlog (a efectos de la planificación) es que da como resultado que todas las historias han sido estimadas con muy poco esfuerzo. Pero no en días/hombre como se haría tradicionalmente. Planning poker produce estimaciones en una medida arbitraria de tamaño llamada story points o «puntos de historia». Los story points son específicos de cada equipo, no pueden compararse entre diferentes equipos y a veces ni siquiera entre diferentes proyectos del mismo equipo. Lo único que indican es el tamaño relativo que tiene cada funcionalidad del backlog respecto a las demás. Lo importante es que ahora tenemos el tamaño total del proyecto estimado en una unidad llamada story points, y esto nos va a servir de mucho.
Priorización
La etapa de priorización es sencilla y depende exclusivamente del Product Owner. Sabiendo ya el tamaño de las historias, debe priorizarlas por valor de negocio. Notar que también es posible comenzar con la asignación de valor y después aportar el tamaño, en todo caso, la priorización se realiza balanceando el valor respecto al coste y respecto a los riesgos de cada objetivo.
Una manera rápida de empezar a asignar valor a las historias es dividirlas en 3 grupos, según sean imperativas, importantes o cosméticas/prescindibles (de manera que si se llega a una fecha de entrega predeterminada y no se han completado por lo menos hemos aportado el máximo de valor posible). Dentro de cada grupo nos resultará más fácil realizar una ordenación relativa por valor y después asignarlo.
La prioridad puede cambiar todo el tiempo; pero el tamaño en story points debe mantenerse fijo con la estimación original (o sea: como regla general, no reestimar). Si aparecen historias nuevas, deben estimarse utilizando el mismo criterio que se utilizó originalmente.
Ahora bien: todo esto todavía no nos dice nada respecto a cuánto durará o costará el proyecto; pero al menos es un paso más respecto a como estábamos antes, que solo teníamos el ballpark estimate. Si sólo pudiéramos averiguar a cuántos días/hombre o días/equipo equivale un story point, tendríamos nuestra estimación, y luego nuestra planificación.
Duración y proyección a partir de la velocidad del equipo
El último paso, por lo tanto, es calcular la velocidad del equipo completando objetivos a lo largo de las iteraciones. Así pues, la velocidad es la cantidad de story points que se completan por iteración. Calcularla es sencilla: solo hay que sentarse y esperar. En dos -como máximo tres- iteraciones, tendrás una idea bastante clara de cuál es la velocidad del equipo y por lo tanto el tamaño y duración del proyecto. Mientras tanto se puede ir construyendo el burndown chart, cosa que no me animo a traducir (gráfico de quemado?). El burndown chart nos muestra en el eje Y la cantidad total de story points del proyecto, y sobre el eje X las iteraciones. Cada vez que se finaliza una iteración, se completa un punto del gráfico, indicando la velocidad en ese ciclo.
Si teníamos una fecha prefijada en la que queremos terminar el proyecto, esto nos permite calcular la velocidad teórica a la que tendremos que ir para alcanzar esa fecha. El burndown chart permite rápidamente y en todo momento ver dos estadísticas vitales para la planificación: la estimación actual de cuándo va a estar terminado el 100% del proyecto; y la estimación del porcentaje de proyecto que va a estar terminado cuando lleguemos a cierta fecha.
Conclusión
La estimación y planificación ágil permiten así en todo momento saber cuál es la fecha estimada de finalización del proyecto, y en qué iteración estará lista determinada funcionalidad. Un beneficio adicional que nos brinda es que de existir complicaciones severas, que pongan en juego la factibilidad del proyecto, éstas generalmente se ven expuestas bien temprano, permitiendo cancelar el proyecto antes de incurrir en grandes pérdidas. Por esto, sumado al hecho de que el desarrollo iterativo e incremental garantiza que en todo momento se cuenta con el producto listo para ser entregado (por ejemplo software funcionado), está el hecho de que los métodos ágiles disminuyen enormemente los riesgos tradicionales en el desarrollo de proyectos.
Artículos relacionados
- Refinamiento de la lista de requisitos y cambios en el proyecto
- Planificación ágil vs planificación tradicional
- Videos cortos sobre planificación ágil

- Planificación ágil con mapas de producto
- Estimación y planificación ágil – Resultados del quinto encuentro ágil en Barcelona
- Creación de Product Backlog – III encuentro ágil en Barcelona
- Planificación ágil de proyectos dependientes
- Métricas ágiles y valor – VI encuentro ágil en Barcelona

Ok ya entiendo , entonces scrum no es tanto para costear un software sino para tener mayor control del tiempo y esfuerzo para terminarlo?. Esto quiere decir que si damos un mal estimado inicial tendriamos que cargar con el costo?.
Me gustaMe gusta
Scrum es un marco para gestionar el desarrollo de un producto, que se basa en equipos autónomos (multidisciplinares y auto-gestionados) que reflexionan regularmente sobre cómo crear un mejor producto de la manera más eficiente posible (y siguiendo los valores y principios del Agile Manifesto).
Dicho esto, hay muchas prácticas del mundo Agile que te pueden ayudar a estimar para un cliente. Por ejemplo https://proyectosagiles.org/2012/11/29/planificacion-agil-mapas-producto/ o https://agilewarrior.wordpress.com/2010/11/06/the-agile-inception-deck/
Una estimación es una estimación, no es una seguridad completa. Para gestionar esto, los valores Agiles se enfocan en ser flexibles para poder dar más valor, es decir, jugar con la variable alcance manteniendo más estables las variables tiempo y coste. Ver: https://proyectosagiles.org/2010/12/15/planificacion-agil-vs-planificacion-tradicional/
Para eso hay que tener el «mindset» de «Customer collaboration over contract negotiation», y si hay que irse a «contract negotiation», en ese caso hay que acordar antes del proyecto las reglas del juego con un «contrato ágil» (es decir, cómo se va a hacer la «gestión e cambios»). Puedes ver más información aquí: https://proyectosagiles.org/2008/11/16/contrato-agil-scrum/
Si tienes problemas para hacer una estimación en un inicio, una de las técnicas Agile que puedes utilizar es hacer un «spike» antes de empezar el proyecto (una prueba de concepto rápida, de usar y tirar), o consultar a un experto, o acordar con el «cliente» que eso no se lo vas a estimar hasta que todo esté más claro… o, si el cliente todavía no forma parte de tu «equipo» y no existe confianza, como última solución vas a tener que acudir a introducir márgenes de protección en el proyecto, cosa que (dado que lo que intentamos en Agile es aumentar la transparencia para tomar mejores decisiones todos juntos y aprender más) no va a ser del todo beneficiosa ni para él ni para ti.
Me gustaMe gusta
Pero no logro comprender si en el método tradicional lo primero que se hace es la toma de requisitos y luego se da un estimado del costo del proyecto?. En scrum me indica que luego de tres iteraciones recien conoceria la estimacion del proyecto?. Pero para la primera iteraccion tengo que darle un estimado al cliente de cuanto cuesta esta iteraccion como hago eso? porque como trabajar sin saber cuanto tengo que cobrar?
Me gustaMe gusta
Hola Francis,
El artículo comenta que «[Antes de iniciar el proyecto] cualquier desarrollador senior puede dar una idea del orden de magnitud de un proyecto. Esto nos brinda lo que en inglés se denomina ballpark figure, un número grueso que nos permite ir pensando si es negocio desarrollar el producto o no. Y es lo primero que debe hacerse, ágil o no ágil.» Pero además, nos dice que utilicemos Historias de Usuario para mejorar nuestro entendimiento de las necesidades en conversaciones con cliente y usuario final… y consecuentemente obtener una mejor estimación inicial. Esta etapa, también conocida como «Inception» se puede realizar de varias maneras. Aquí puedes encontrar una técnica: https://proyectosagiles.org/2012/11/29/planificacion-agil-mapas-producto/
Lo que se comenta en el artículo acerca de «tres iteraciones, para tener una idea más clara de cuál es la velocidad del equipo y por lo tanto la duración del proyecto» se refiere a tener un control empírico sobre el progreso real y cuánto falta para acabar (más allá de la estimación inicial). Ver: https://proyectosagiles.org/2010/12/15/planificacion-agil-vs-planificacion-tradicional/
Espero haber ayudado,
Xavier Albaladejo
Me gustaMe gusta
Hola Xavier,
Agradecido por el hecho de que compartas tus conocimientos y promuesvas esta metodología.
Quiero saber qué papel juegan las estructuras WBS en donde normalmente se definen las funcionalidades con las metodologías tradicionales.
Muchas gracias!!
Me gustaMe gusta
Hola Ricardo,
El WBS se realiza en la planificación de iteración (Sprint Planning), asociando a cada objetivo las tareas necesarias para conseguirlo. Esto tiene varios beneficios, entre ellos el de retardar las planificación y estimaciones detalladas (según los principios Lean). Si se avanzasen, los cambios del contexto del proyecto las harían rápidamente obsoletas.
Ver también Planificación ágil vs planificación tradicional
Me gustaMe gusta
Hola que tal,me encanto esta página, sucede que me estoy adentrando al proceso ágil, como ex-encargado de planeacion de un centro de desarrollo de mi universidad vengo usando el metodo tradicional desde hace mucho y estoy viendo la posibilidad de agilizar dicho lugar.
SOLO UNA DUDA…
¿En que momento se diseña la arquitectura del sistema? es decir los diagramas de baja fidelidad? Porque veo que en el proceso ágil se enfocan en seguir el Product Backlog.
O en el proceso ágil no se utiliza un diseño de diagramas? es decir de los requerimientos se saltan al proceso de programación basado en la priorización del Product Backlog?
Tulio
Me gustaMe gusta
Hola Tulio,
La metodología de trabajo para la construcción del producto (tareas a realizar, entregables a generar) depende de las necesidades del proyecto, del equipo, etc.
En el caso que comentas, un primer esbozo del modelo de arquitectura de sistema se puede hacer en la llamada “Iteración 0”, bien a nivel de producto y/o sólo de la parte a construir para la próxima release (el contexto del proyecto cambiará), con el grado de detalle suficiente para entender qué componentes hay que desarrollar, identificar las integraciones a realizar y tener esto en cuenta las restricciones que puedan aparecer en la planificación del Product Backlog, así como pruebas de concepto a incorporar.
Los diagramas más detallados se elaboran de manera colaborativa (con la participación de todo el equipo) en la segunda parte reunión de planificación de la iteración. Se pueden ir refinando durante la propia iteración en función de las necesidades del equipo y del objetivo que tengan esos modelos.
Salud,
Xavier Albaladejo
Me gustaMe gusta
Felicidades por el artículo. Muy bien redactado y enlazado.
Tengo algunas preguntas:
1) Si se estima en story points que es una unidad relativa, ¿por dónde se empieza? Yo tenía entendido que estimaba en horas/días/X (pero en definitiva, una unidad de medida temporal), y si sale infinito se subdivide hasta que la tarea sea lo suficientemente pequeña como para poder estimarla.
2) También tenía entendido que la velocidad se calculaba desde la primera iteración. Bueno, realmente la primera velocidad es una cuenta rápida: nº desarrolladores * días de duración del sprint * factor de foco. Como esta unidad es temporal (días), se supone que la unidad de estimación del product backlog también debería serlo.
Me gustaMe gusta
Hola Álvaro,
La clave al estimar en story points es olvidarse de los días hombre por un rato. Esto nos permite pensar en la complejidad del problema, en vez de perdernos en detalles de implementación y cosas propias del equipo.
Para empezar, se toma una historia que, a ojo, parezca una de las más pequeñas del backlog. A esa historia le damos tamaño un story point. (Algunos prefieren darle tamaño dos story points, para dejar lugar a que aparezca algo más pequeño más adelante.) Luego se procede a estimar todo el backlog secuencialmente, usando esta escala. Cada historia se compara con las anteriores -ya estimadas- para orientarse respecto a su tamaño.
El cálculo de Velocidad se puede hacer -desde ya- desde la primera iteración, pero al no haber ningún tipo de información histórica, tiene tanto valor como una adivinanza. En general uno toma el total de story points que el equipo decidió podía completar como referente a lo que el equipo piensa que va a ser su velocidad. Siempre medido en story points. Luego, al concluir la iteración, se mide el número de story points que fueron realmente entregados (demostrados y aceptados por el Product Owner).
Sabiendo el numero de story points terminados, más la cantidad de días hombre que fueron “gastados” en la iteración, es tarea sencilla hacer la conversión entre “story points” y “días/hombre”. Tener en cuenta que este número puede variar más adelante, a medida que el equipo mejora (por ejemplo al rendir fruto sus retrospectivas) o empeora (por ejemplo al acumular deuda técnica)
Saludos,
Xavier
Me gustaMe gusta
Hola,
En Primer lugar disculparme si este no es el lugar adecuado para la siguiente duda, pero no conozco el site y la verdad es que necesito ayuda.
Tengo la siguiente duda respecto al seguimiento del SPRINT. Muchos autores dicen que en el SPRINT PLANNING las user stories no tienen porque dividirse completamente en tareas, ya que esto consumiría mucho tiempo y se puede ir hacienda a medida que avanza el SPRINT. Por tanto al final del SPRINT PLANNING la unica estimacion que tenemos son las user stories en story points.
Una vez Comienza el sprint. Tenemos que hacer un seguimiento para ver como vamos avanzando. Por lo que he visto que habitualmente se utiliza BurnDown Chart. Desde mi punto de vista nos podemos encontrar con 2 posibilidades:
1. Las User stories no se han dividido en tareas, es decir la unica medida son los STORY POINTS. Por tanto el grafico tendra que mostrar story points versus dias… Como actualizamos el grafico para realizar el seguimiento?
Hasta que no acabemos una User Story no sabremos con certeza cuanto avance llevamos. QUe hacemos?
a. Estimamos cuantos story points hemos completado.
b. Esperamos a concluir la User Story para entonces incluir todos los puntos en el grafico.
En ninguno de los 2 casos el grafico nos muestra una situacion real.
2. Las User Stories se han dividido en tareas y las tareas estan estimadas en horas. El grafico muestra el progreso de una forma mas tangible, aunque tambien es cierto que si una vez el sprint ha acabado y alguna user story en la que habiamos empezado a trabajar (y reamente habiamos acabado alguna tarea) no la hemos completado, este avance que habiamos indicado se pierde y nos encontramos con que acabemos peor de lo que indicabamos el dia anterior.
Saludos.
Me gustaMe gusta
El objetivo del Sprint Planning es entender cuál es el objetivo del Sprint, QUÉ es lo que el Product Owner ha priorizado para desarrollar y pensar juntos CÓMO hacerlo, mirando si cabe en el Sprint. Para ello se identifican tareas, se hacen diagramas o lo que sea necesario para tener una previsión razonable de QUÉ se va a poder enseñar al final del Sprint.
En todo este proceso hay que utilizar el sentido común:
– Sobre el nivel de granularidad de las tareas:
– Ha de ser el suficiente como para que el equipo esté cómodo respecto a la estrategia de cómo conseguir el objetivo del Sprint.
– Ha de permitir ver el progreso en el Sprint (sea en el tablero físico y/o con un burndown) y tomar decisiones a tiempo si no se llega.
– Sobre la medida de progreso:
– Puede ser por horas que falten para acabar, puntos de historia, número de tareas… lo que sea más cómodo, pero que sea claro y visible para el equipo en todo momento.
– Para no engañarnos a nosotros mismos, dado que trabajamos orientados a objetivos (historias de usuario) y no tareas o a hacer horas, la mejor medida de progreso es el número de historias que tenemos completadas en el Sprint 🙂 Esto también nos fuerza a cerrar objetivo por objetivo, a colaborar entre los diferentes miembros del equipo para conseguir sinergias y aprendizaje cruzado (y así evitar que una persona haga una historia de usuario por completo, o peor, que alguien siempre haga el mismo tipo de historias de usuario, por que estaríamos creando una punto único de ruptura en el equipo, nuestro truck factor sería 1). Si la «situación real» es que estamos trabajando con muchas historias de usuario en paralelo (con lo que no vemos progreso), entonces es que tenemos un problema con nuestra «situación real»… por ejemplo finalizarlo todo casi el último día (nos estamos saltando el principio de trabajar iterativa e incrementalmente dentro del Sprint).
– En todo caso, siempre hay que usar el sentido común. Si un burndown de tareas también podría funcionar, ¿por qué no hacer una prueba para ver si su ayuda? 🙂
Por último, el objetivo nunca es tener un sistema de métricas perfecto, sino ayudarnos a pensar en cómo mejorar, donde están nuestros problemas, cómo colaborar más y tener unas previsiones de objetivos hechos al final del Sprint cada vez un poco más fiables.
Me gustaMe gusta